log
assets
第二节讲义_1682136737988_0
{kind=link}
{kind=link}
_-_image_1705670873910_0.png){kind=link}
_-_image_1705670919100_0.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
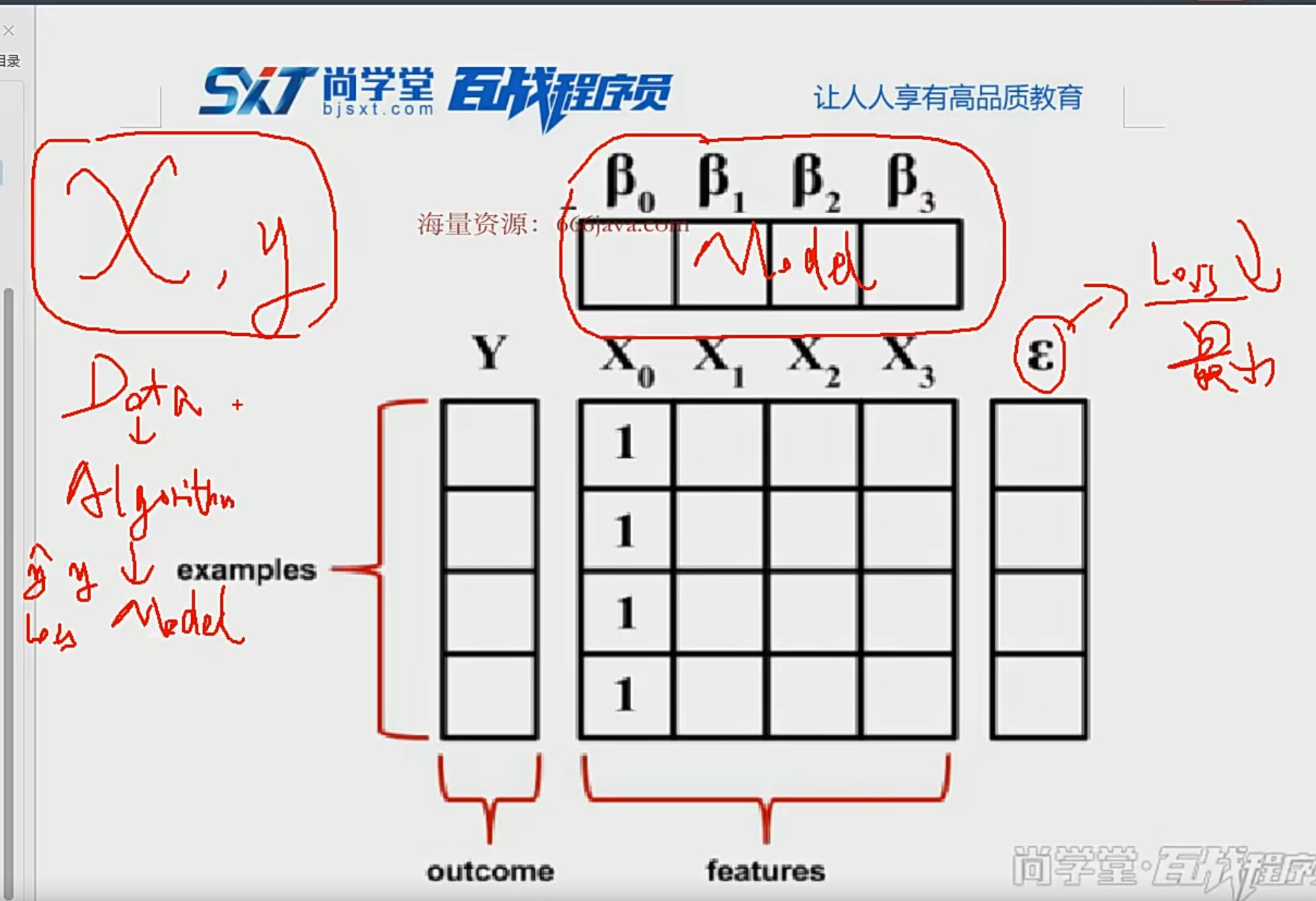{kind=link}
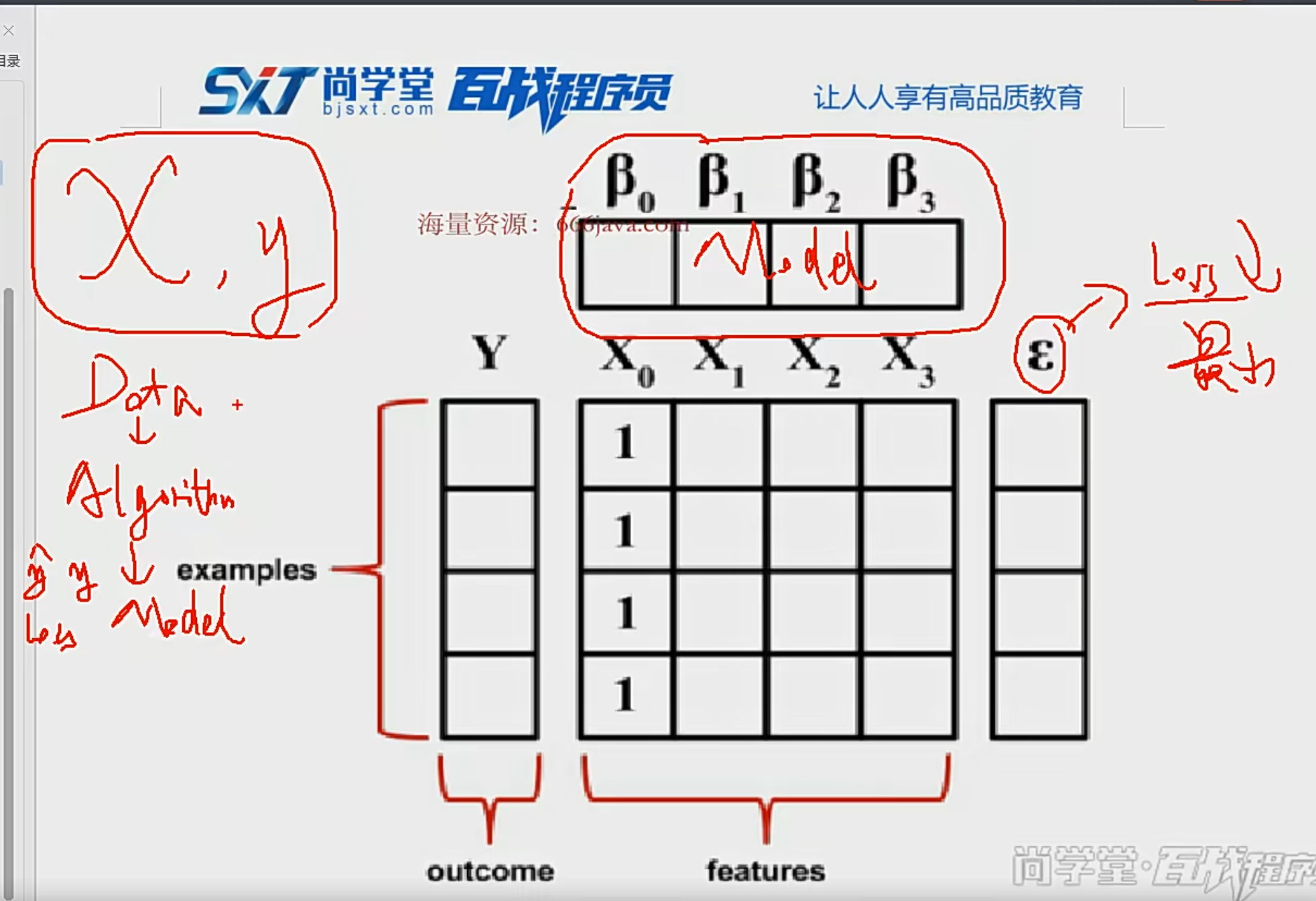{kind=link}
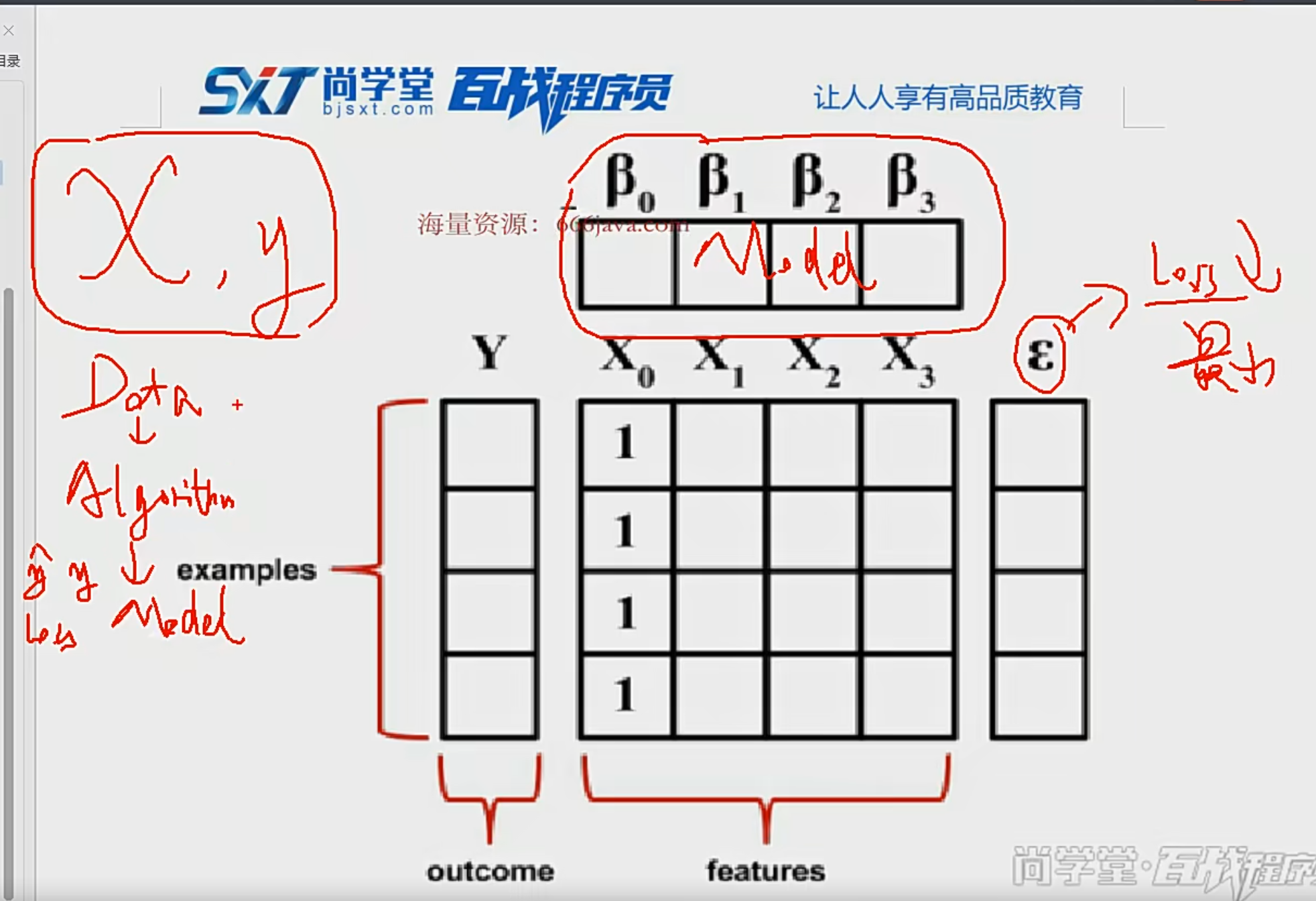{kind=link}
{kind=link}
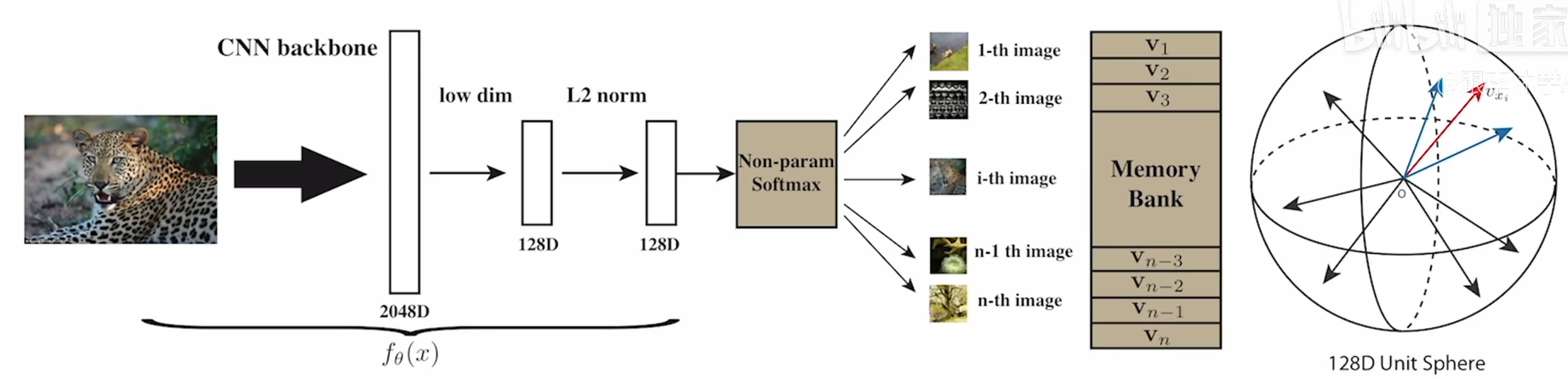{kind=link}
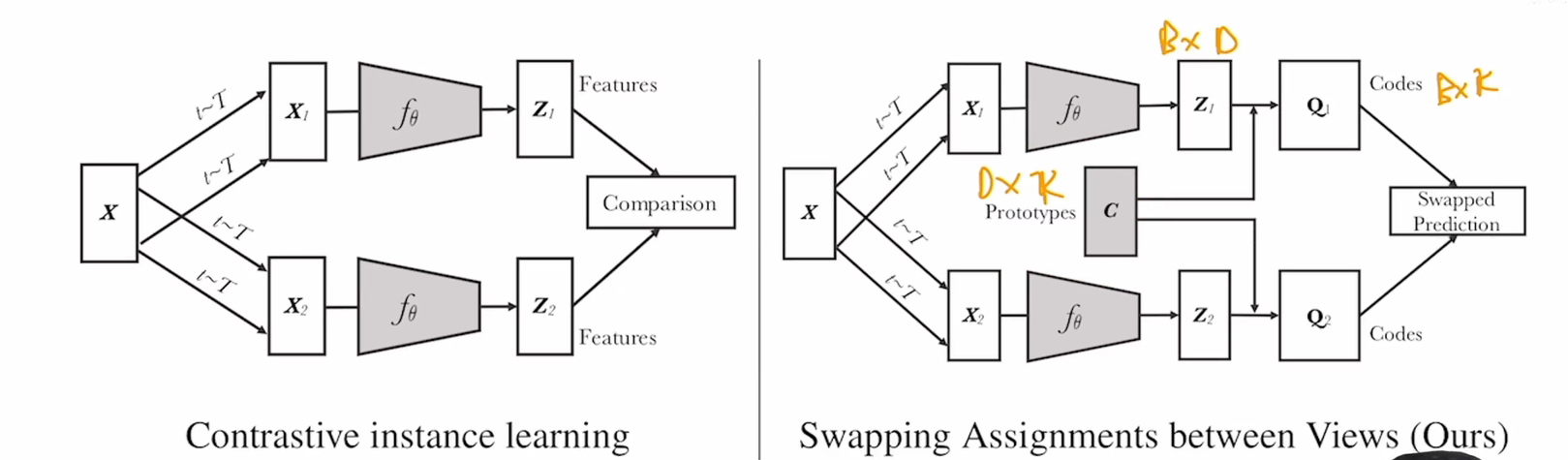{kind=link}
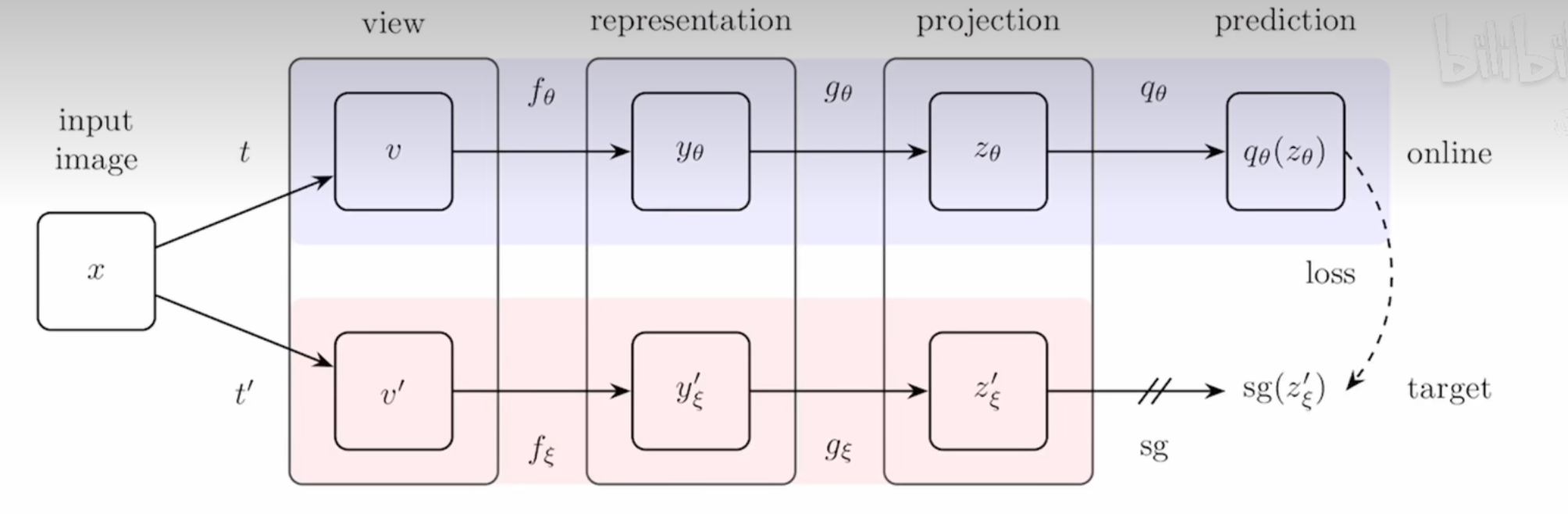{kind=link}
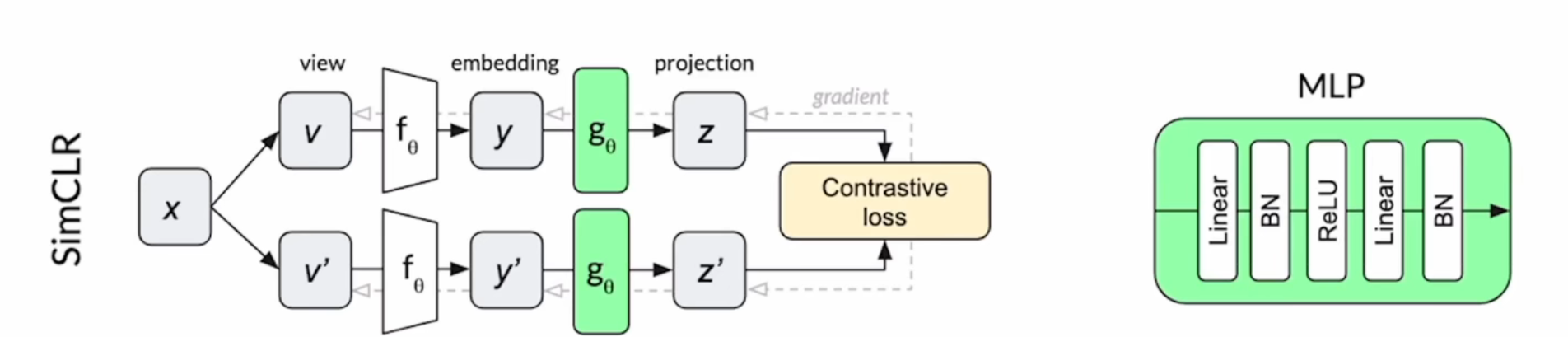{kind=link}
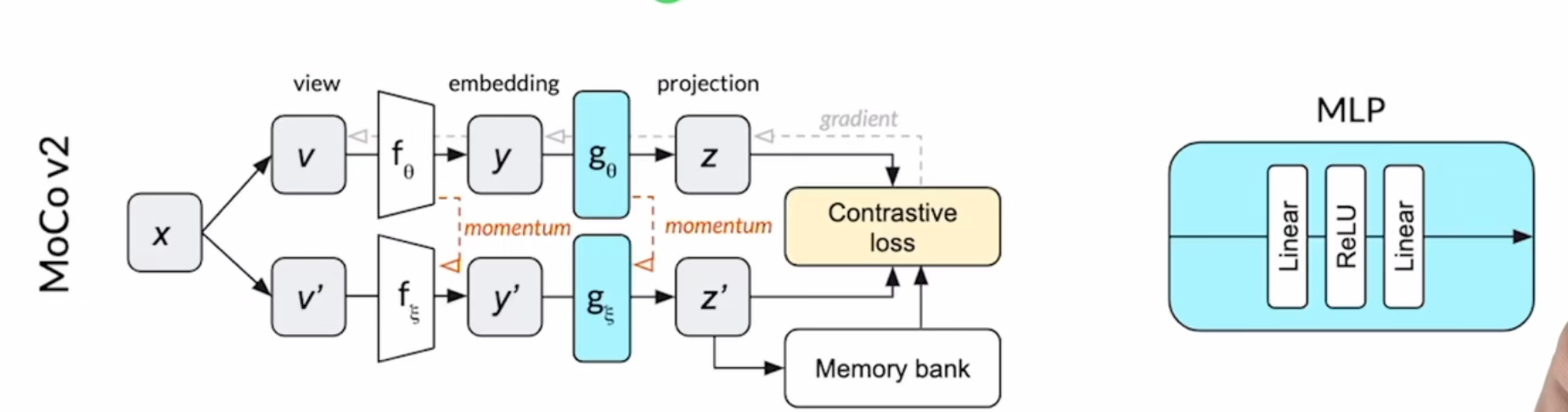{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
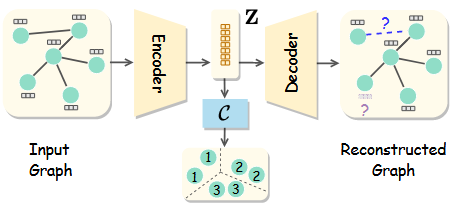{kind=link}
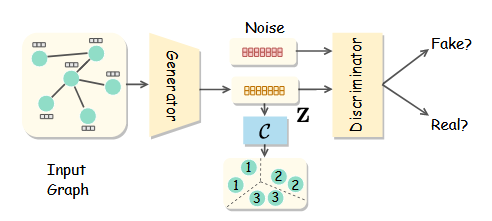{kind=link}
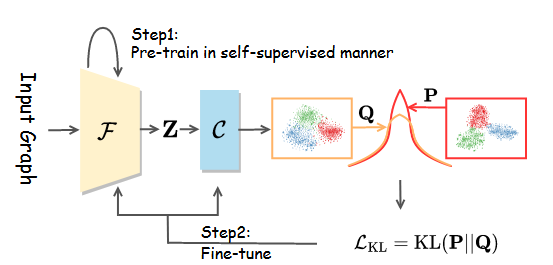{kind=link}
{kind=link}
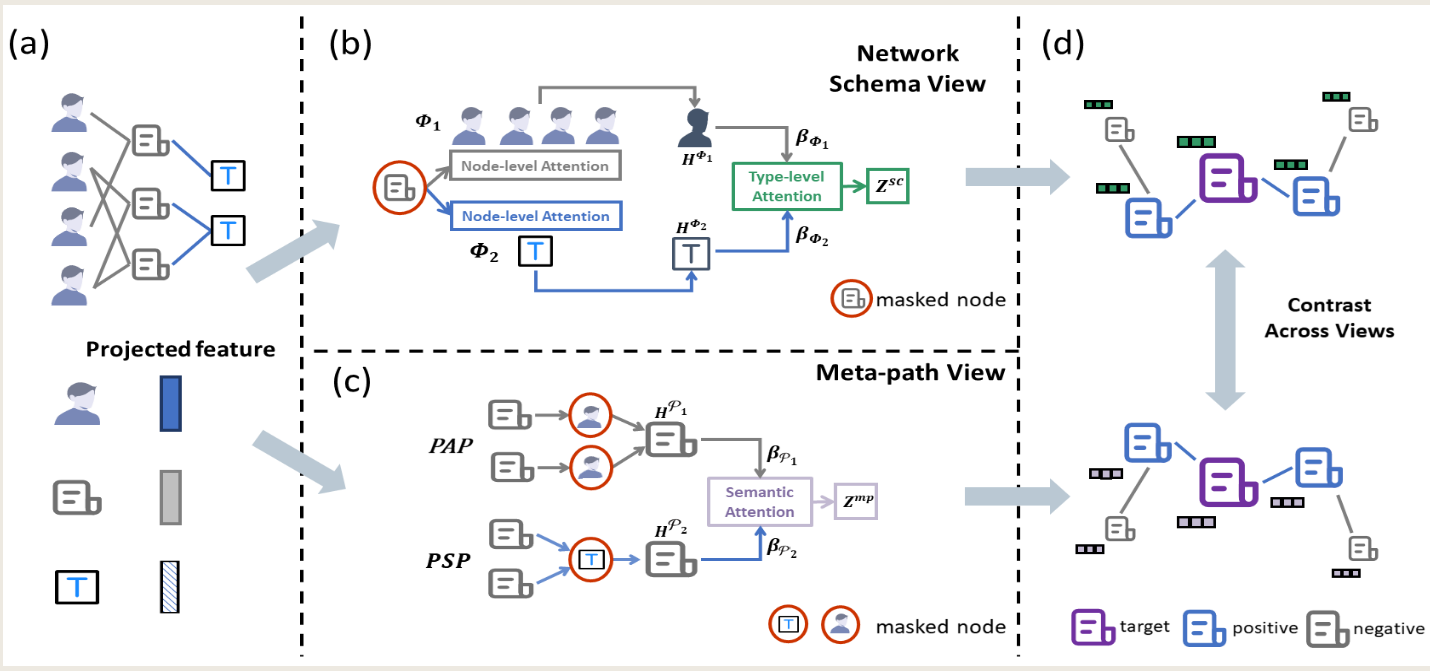{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
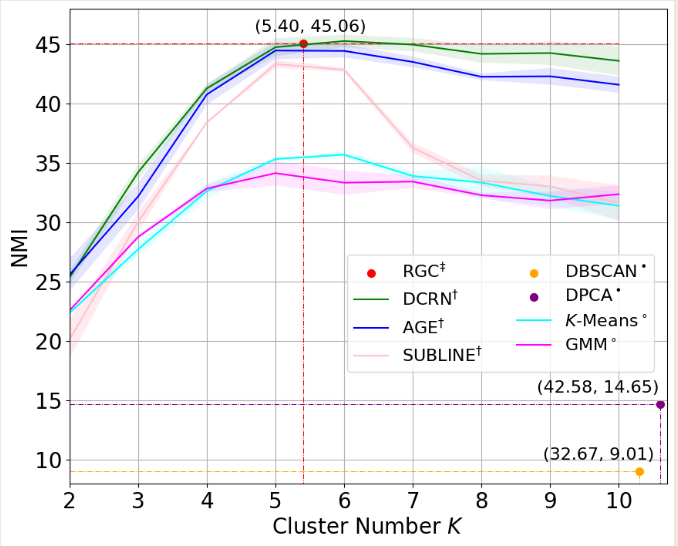{kind=link}
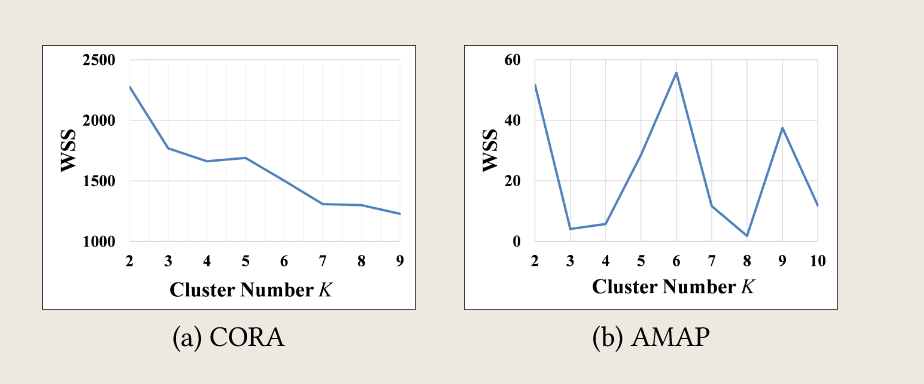{kind=link}
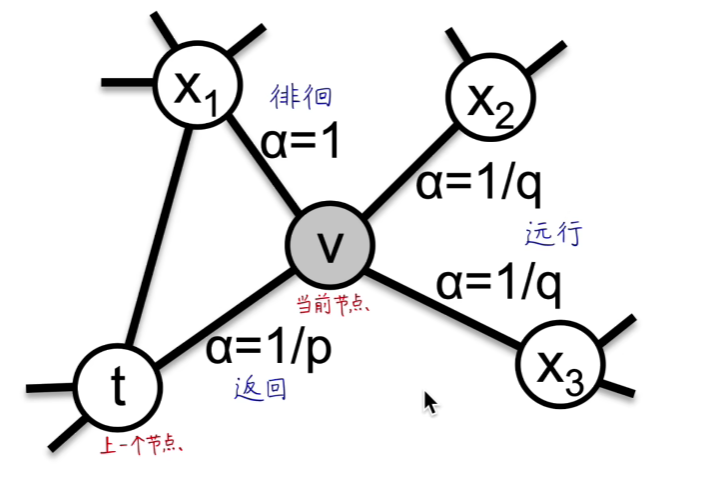{kind=link}
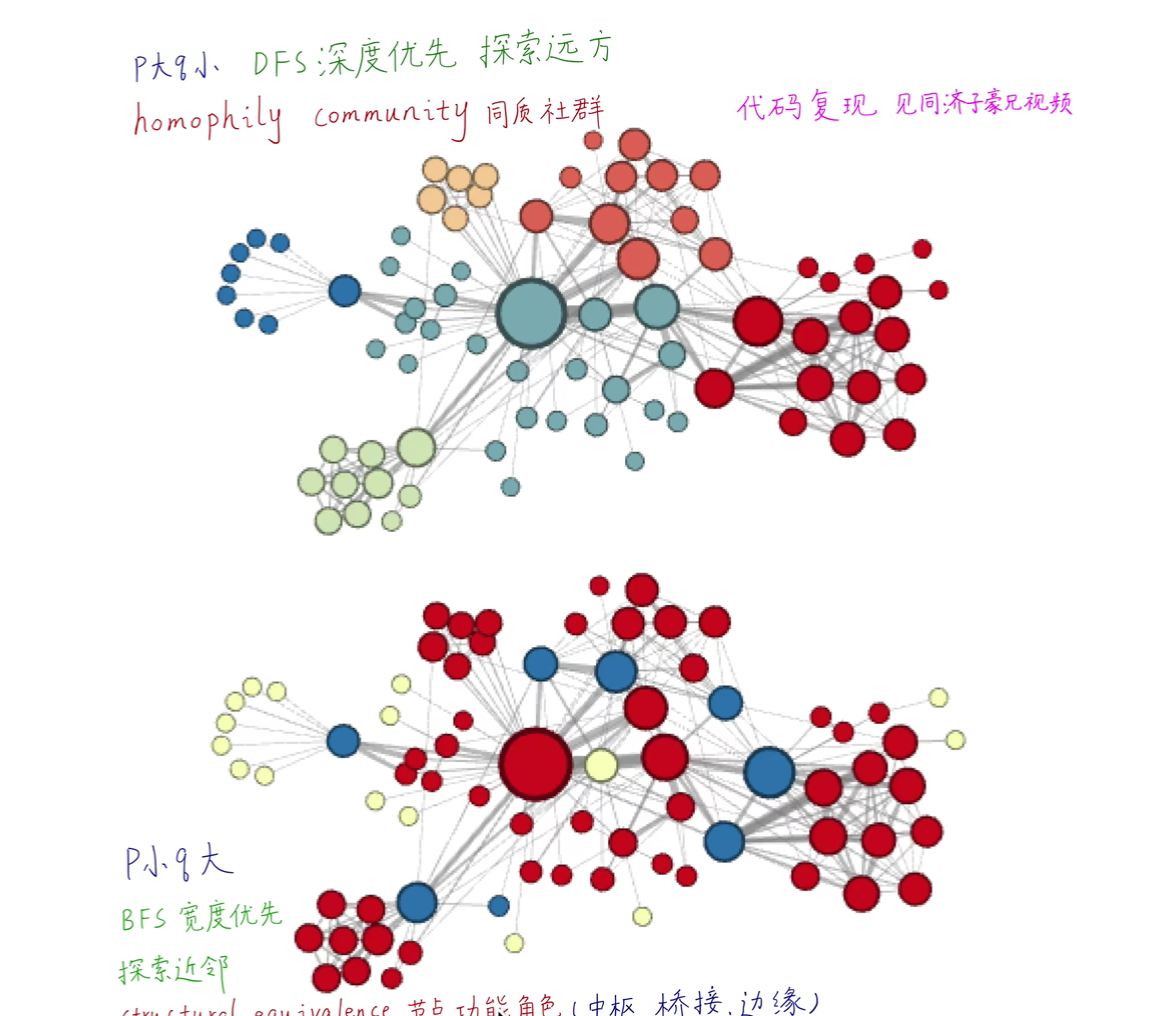{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
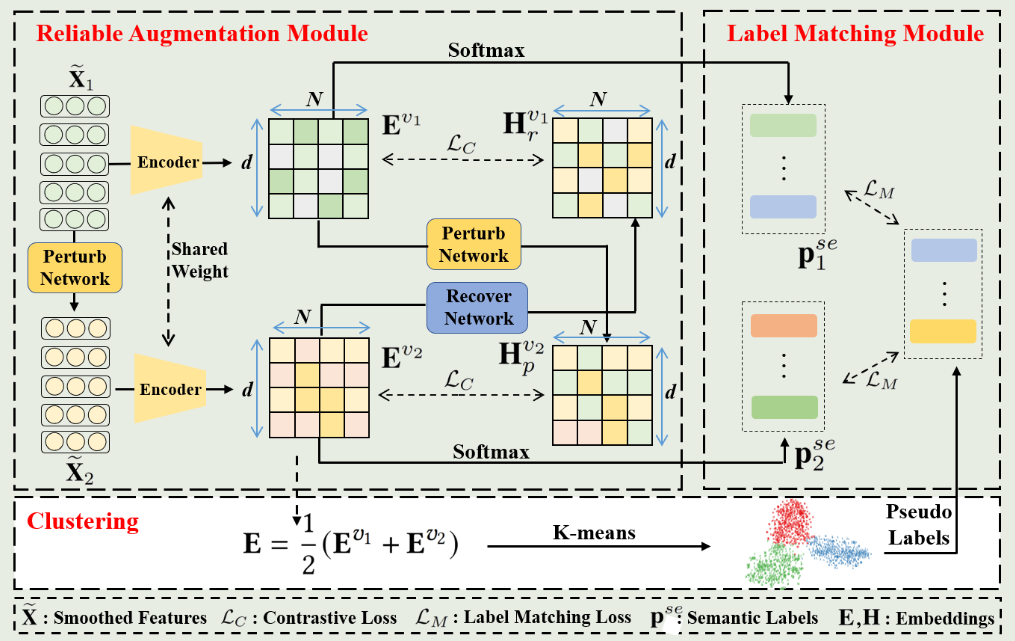{kind=link}
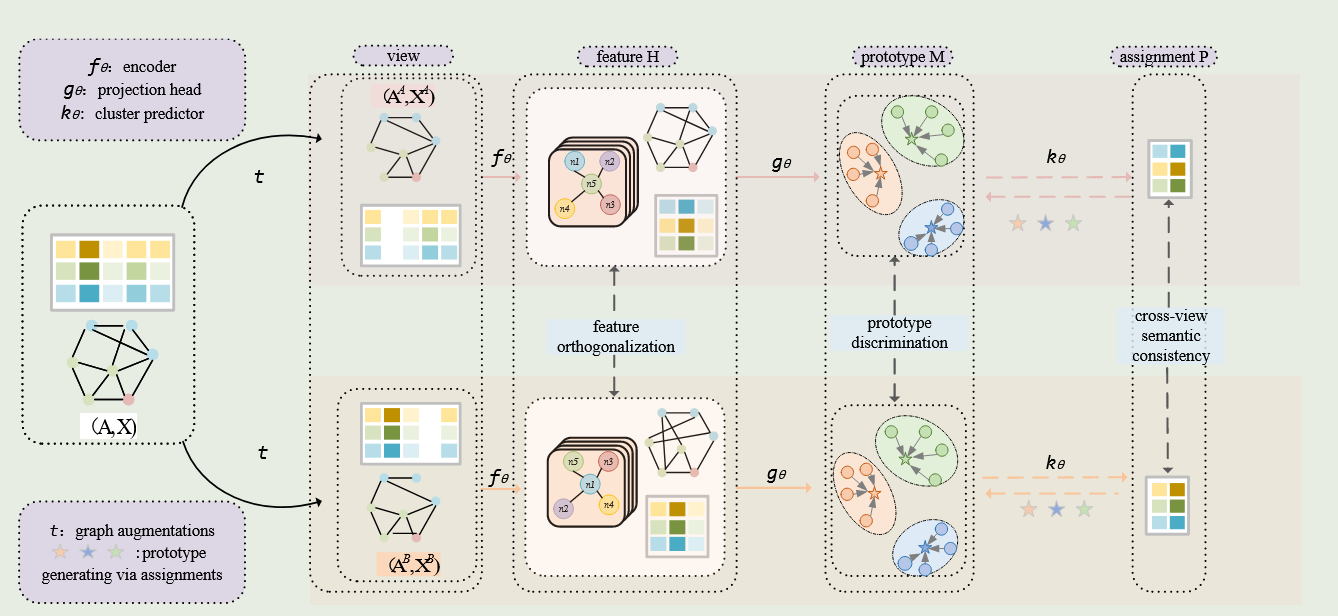{kind=link}
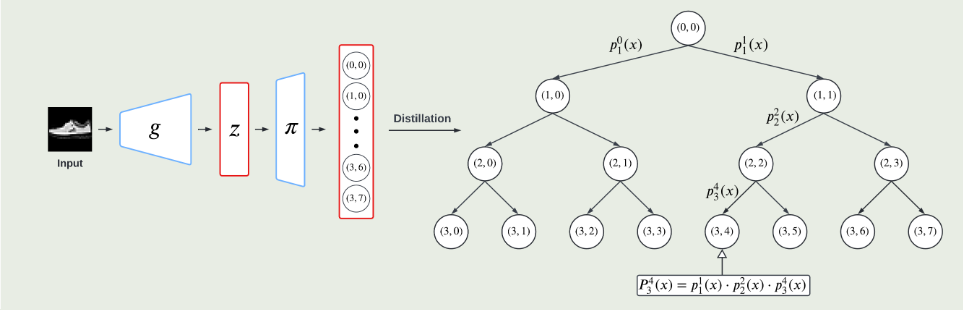{kind=link}
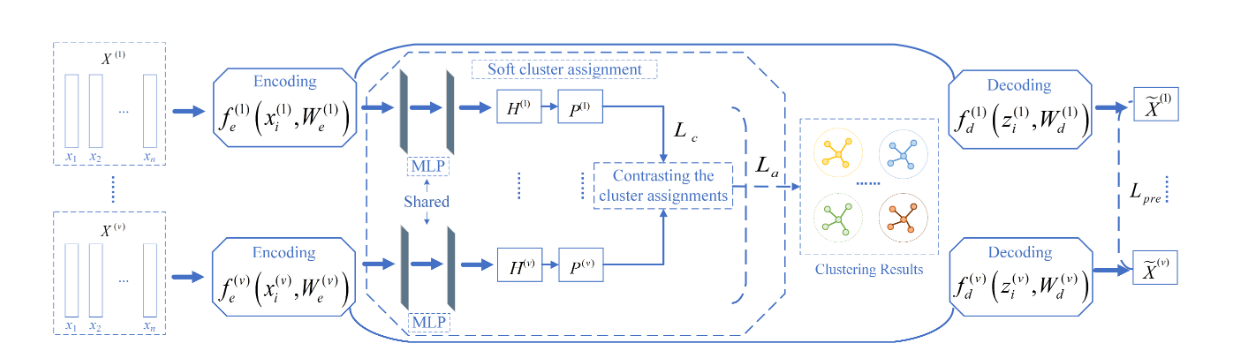{kind=link}
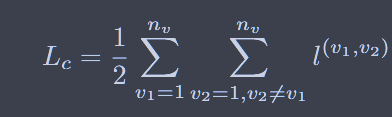{kind=link}
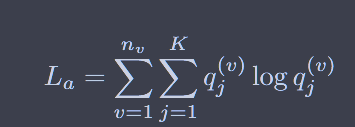{kind=link}
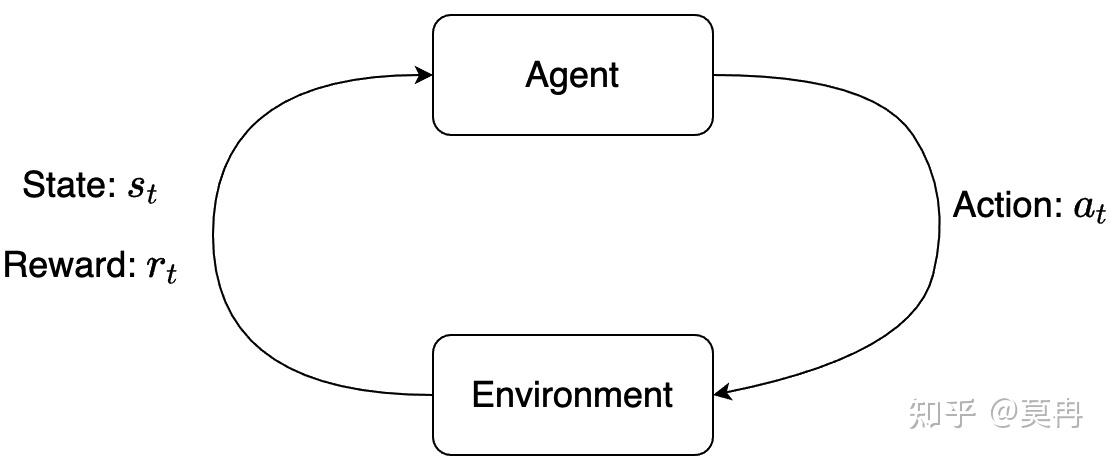{kind=link}
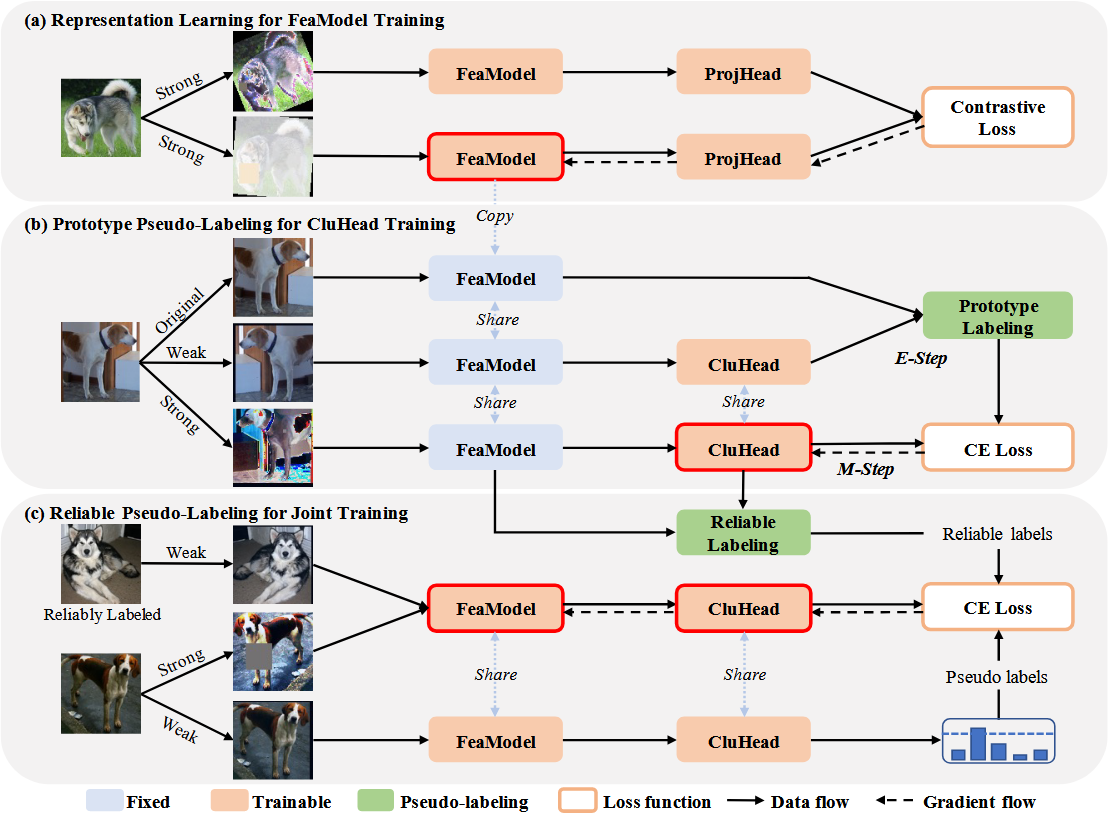{kind=link}
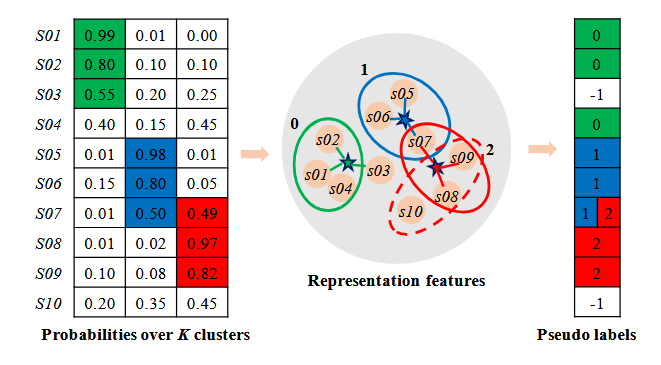{kind=link}
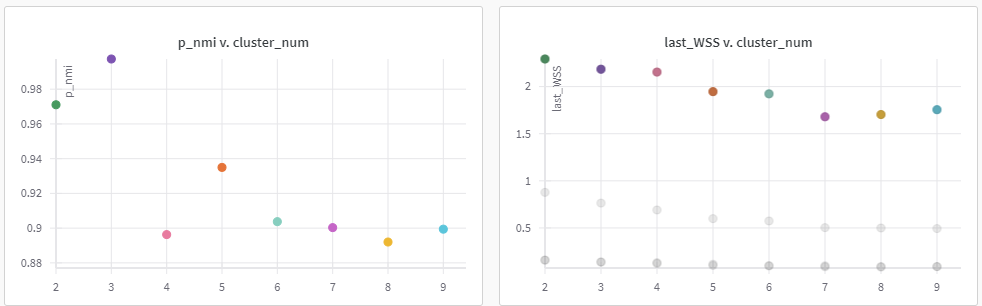{kind=link}
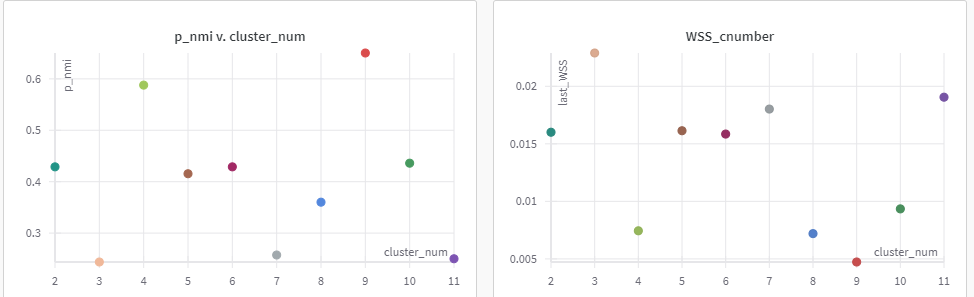{kind=link}
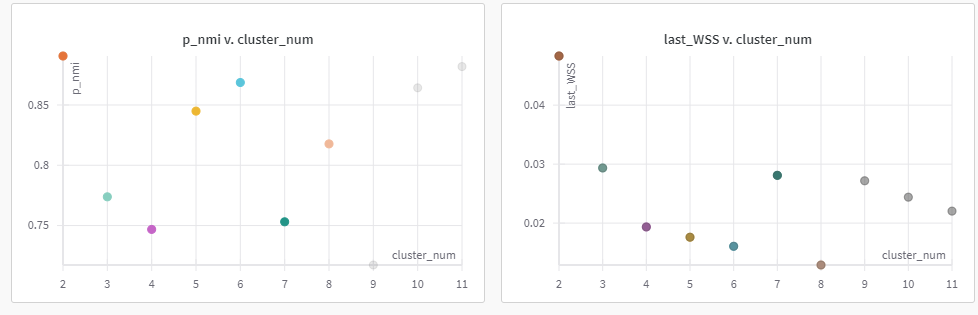{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
journals
loom
pages
static
css
{kind=link}
fonts
inter
icons
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
img
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
js
excalidraw-assets
locales
pdfjs
cmaps
tags
2024_01_19
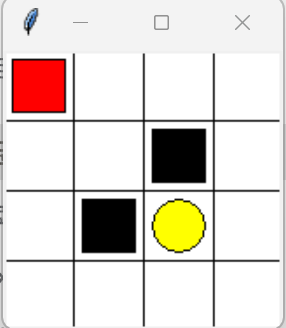
- 强化学习 玩
- act,env,state
- get_env_back 根据act和当前状态s更新状态s和奖励
- choose_act 根据当前q表和env决定action
- 当然啦,需要更新环境:开始时,更新。每一步结束时,更新。
- step,环境s以及轮次
- 既然如此,玩:
- qtable是共享的,s也是共享的
- choose_act
- 当γ>0.9或者q表值全为0的时候,随机选择
- 否则,选择q表对应s状态下的最大值
- get_env_back(action,state)

- 注释:当choose_act后,对应状态应该发生改变
- 那么,需要什么呢?之前的状态,以及state,action
- 需要返回什么?
- 如果选择为右侧,并且下一个步骤为right,那么,s返回结束,更新奖励1
- 否则,则更新state-1,R为0
- 主代码部分:
- choose_act
- state,r=get_env_back
- predict=如果新状态不是终止,则旧加现在更新
- 终止,则真实值为R
- Q(s,a)=Q(s,a)+α[r+γtrue-Q(s,a)]
-
Table Of Contents